操作系统实验二--进程通信与内存管理
进程的软中断通信
查看帮助手册
fork系统调用
使用man命令查看fork系统调用结果如下图:
可见结果显示没有相应的条目,猜测可能没有安装man帮助手册,通过以下资料查阅安装man手册。
使用的安装命令及结果如下图: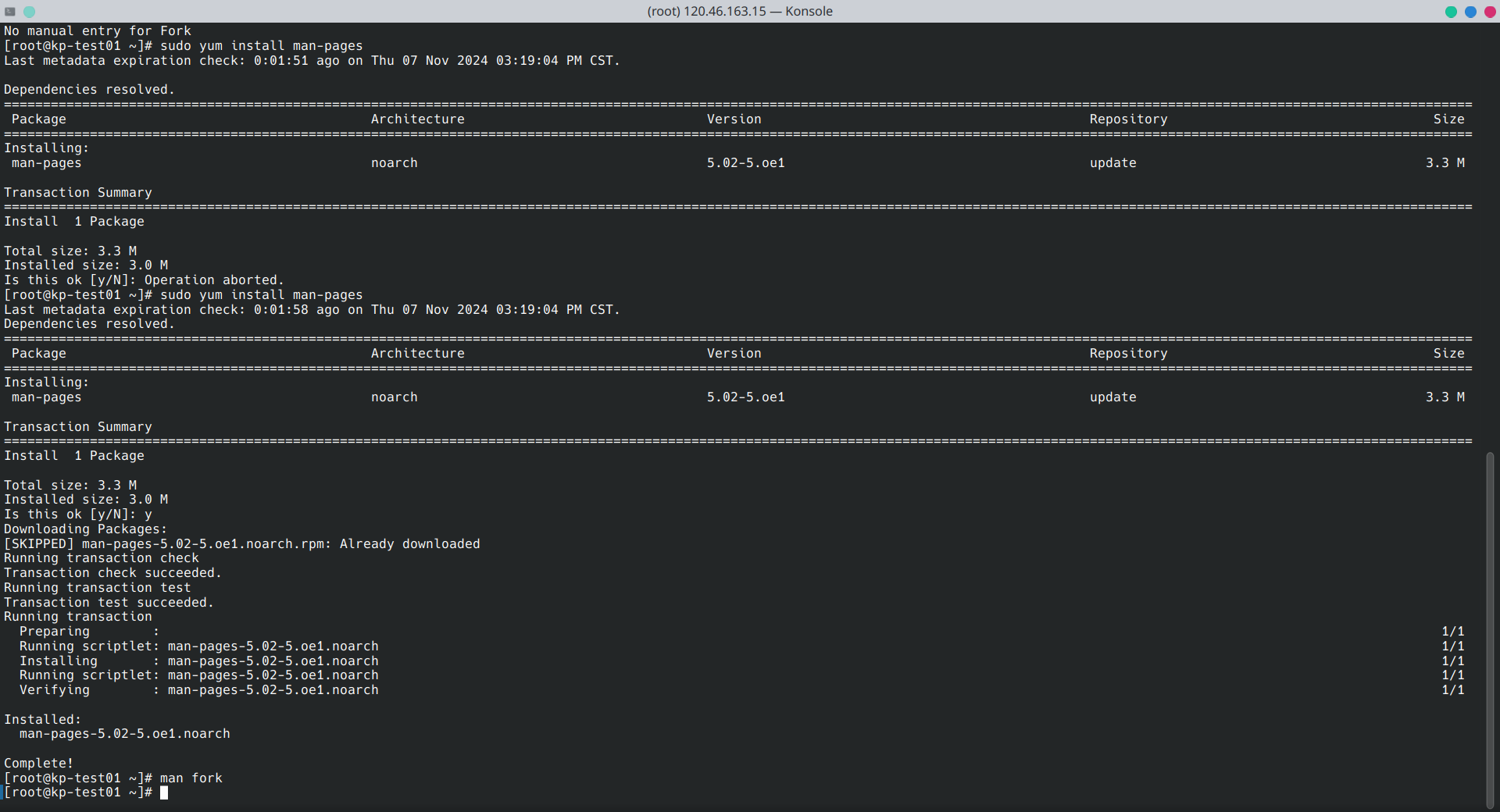
可见在安装好man手册,成功使用man fork命令,如下图:
kill系统调用
结果如下图:
signal系统调用
sleep系统调用
exit系统调用
软中断程序
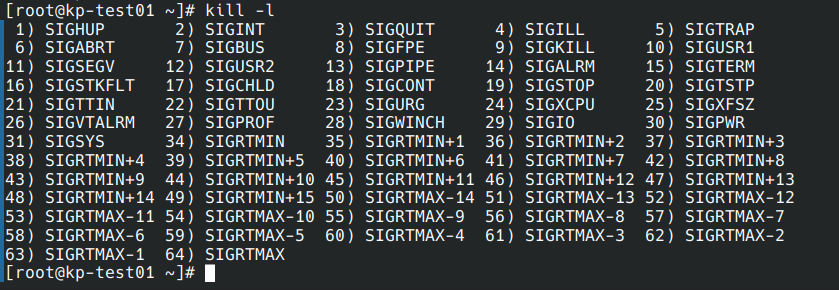
openEuler系统下,使用命令kill -l查看所有信号及其编号的结果如下:
补充完成进程软中断的程序代码如下,其中对于等待时间的要求,考虑到sleep过程可以被信号打断,选择通过sleep函数实现:
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <signal.h>
int flag = 0;
pid_t pid1 = -1, pid2 = -1;
void inter_handler(int signum)
{
// 使用 kill() 发送整数值为 16 和 17 的信号
if (pid1 > 0) kill(pid1, 16); // 发送信号 16 给子进程1
if (pid2 > 0) kill(pid2, 17); // 发送信号 17 给子进程2
printf("Parent received signal %d, sending signals 16 and 17 to child processes\n", signum);
}
void waiting(int signum)
{
printf("Child process received signal %d, exiting...\n", signum);
exit(0);
}
int main()
{
// 创建子进程1
while (pid1 == -1) pid1 = fork();
if (pid1 > 0)
{
// 创建子进程2
while (pid2 == -1) pid2 = fork();
if (pid2 > 0)
{
// 父进程
signal(SIGINT, inter_handler);
signal(SIGQUIT, inter_handler);
wait(NULL);
wait(NULL);
printf("\nParent process is killed!!\n");
}
else
{
// 子进程2
signal(17, waiting);
sleep(5);
printf("\nChild process 2 is waiting for signal 17...\n");
}
}
else
{
// 子进程1
signal(16, waiting);
sleep(5);
printf("\nChild process 1 is waiting for signal 16...\n");
}
return 0;
}
分别在5s内进行操作和不进行操作,编译运行结果如下:
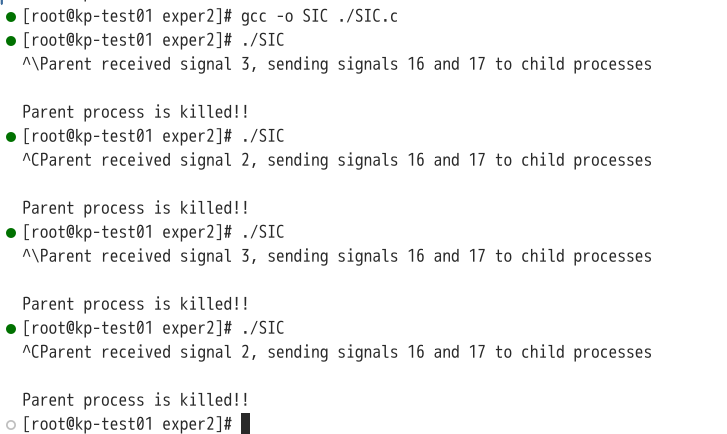

可以发现在5s内进行操作后,父进程虽然发送了信号,但子进程没有接收到或者没有处理。考虑到在 UNIX 和 Linux 系统中,SIGINT 、SIGQUIT信号默认会发送给整个进程组(包含父进程和子进程)。当在shell进行操作时,由于子进程没有设置相应的信号处理程序,在缺省的情况下默认终止进程或者终止进程并进行内核映像转储,导致子进程在接受到父进程传递的16、17信号前已经先一步终止。 故修改代码,在子进程中将SIGINT、SIGQUIT信号阻塞。 修改后代码如下:
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <signal.h>
int flag = 0;
pid_t pid1 = -1, pid2 = -1;
void inter_handler(int signum)
{
// 使用 kill() 发送整数值为 16 和 17 的信号
if (pid1 > 0) kill(pid1, 16); // 发送信号 16 给子进程1
if (pid2 > 0) kill(pid2, 17); // 发送信号 17 给子进程2
printf("Parent received signal %d, sending signals 16 and 17 to child processes\n", signum);
}
void child_handler(int signum)
{
if(signum == 17)
{
flag = 1;
}
printf("Child process%d received signal %d, exiting...\n", flag+1, signum);
exit(0);
}
int main()
{
sigset_t parent;
sigemptyset(&parent);
sigaddset(&parent, SIGINT);
sigaddset(&parent, SIGQUIT);
// 创建子进程1
while (pid1 == -1) pid1 = fork();
if (pid1 > 0)
{
// 创建子进程2
while (pid2 == -1) pid2 = fork();
if (pid2 > 0)
{
// 父进程
signal(SIGINT, inter_handler);
signal(SIGQUIT, inter_handler);
wait(NULL);
wait(NULL);
printf("\nParent process is killed!!\n");
}
else
{
// 子进程2
sigprocmask(SIG_BLOCK, &parent, NULL);
signal(17, child_handler);
sleep(5);
printf("\nChild process 2 is waiting for signal 17...\n");
}
}
else
{
// 子进程1
sigprocmask(SIG_BLOCK, &parent, NULL);
signal(16, child_handler);
sleep(5);
printf("\nChild process 1 is waiting for signal 16...\n");
}
return 0;
}
此时,编译后在5s内分别进行操作与不进行操作的结果如下图:
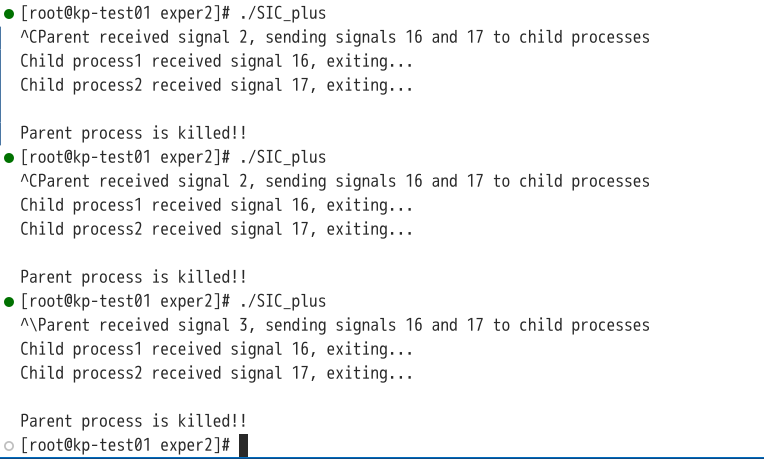

如图可见,子进程成功的接受到父进程的中断信号,结果符合猜想。 考虑到实验指导书程序流程图中,要求在5s内不进行操作时,父进程接受SIGALRM信号,产生软中断SIGALRM,调用kill函数终止子进程,而不是使用sleep函数,修改代码如下:
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <signal.h>
int flag = 0;
pid_t pid1 = -1, pid2 = -1;
void inter_handler(int signum)
{
// 使用 kill() 发送整数值为 16 和 17 的信号
if (pid1 > 0) kill(pid1, 16); // 发送信号 16 给子进程1
if (pid2 > 0) kill(pid2, 17); // 发送信号 17 给子进程2
printf("Parent received signal %d, sending signals 16 and 17 to child processes\n", signum);
}
void child_handler(int signum)
{
if(signum == 17)
{
flag = 1;
}
printf("Child process%d received signal %d, exiting...\n", flag+1, signum);
exit(0);
}
int main()
{
sigset_t parent;
sigemptyset(&parent);
sigaddset(&parent, SIGINT);
sigaddset(&parent, SIGQUIT);
// 创建子进程1
while (pid1 == -1) pid1 = fork();
if (pid1 > 0)
{
// 创建子进程2
while (pid2 == -1) pid2 = fork();
if (pid2 > 0)
{
// 父进程
signal(SIGINT, inter_handler);
signal(SIGQUIT, inter_handler);
signal(SIGALRM, inter_handler);
alarm(5);
wait(NULL);
wait(NULL);
printf("\nParent process is killed!!\n");
}
else
{
// 子进程2
sigprocmask(SIG_BLOCK, &parent, NULL);
signal(17, child_handler);
while(1);
printf("\nChild process 2 is waiting for signal 17...\n");
}
}
else
{
// 子进程1
sigprocmask(SIG_BLOCK, &parent, NULL);
signal(16, child_handler);
while(1);
printf("\nChild process 1 is waiting for signal 16...\n");
}
return 0;
}
编译后,在5s内分别进行操作与不进行操作的结果如下:
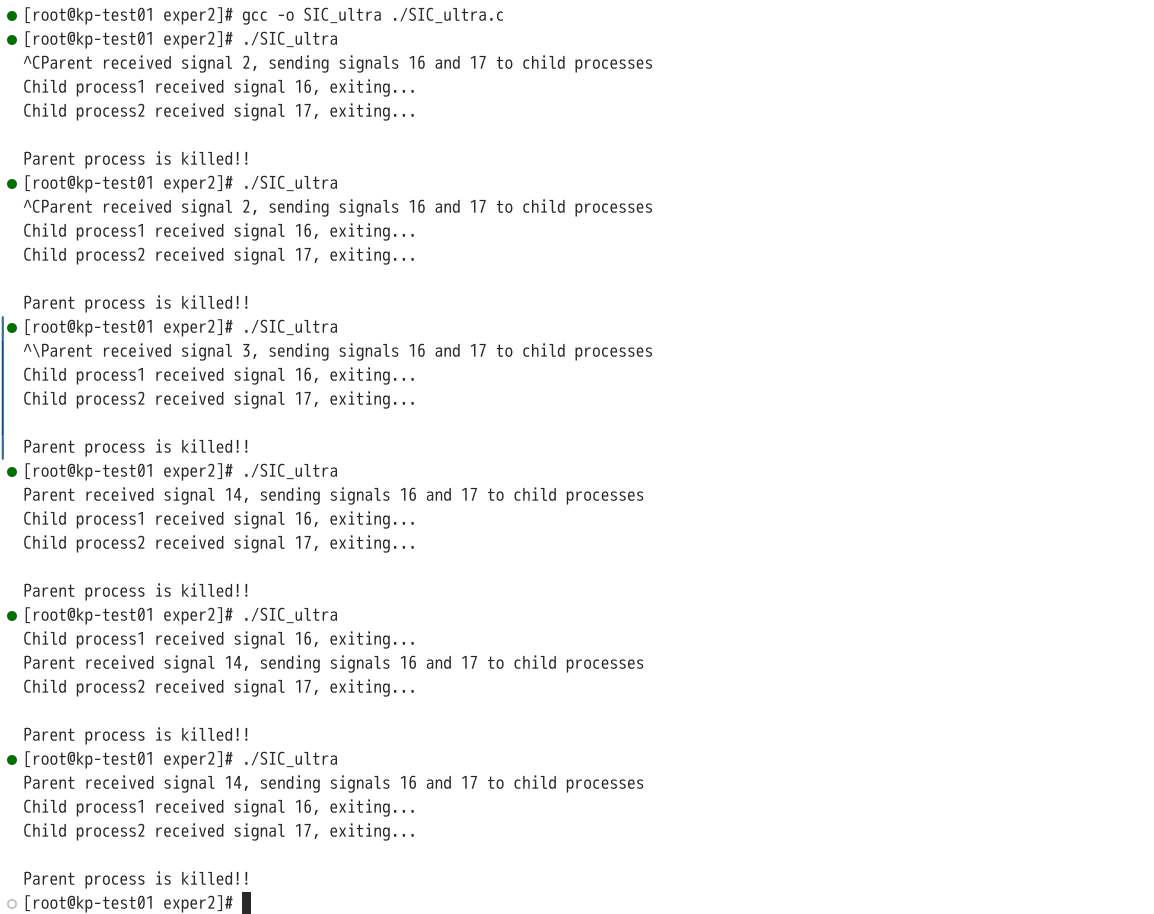
如图所示,可见结果符合预期。
进程的管道通信
资料查阅
考虑到在代码中需要使用pipe命令创建管道,使用lockf为创建的管道加锁,使用man命令查看帮助手册有:
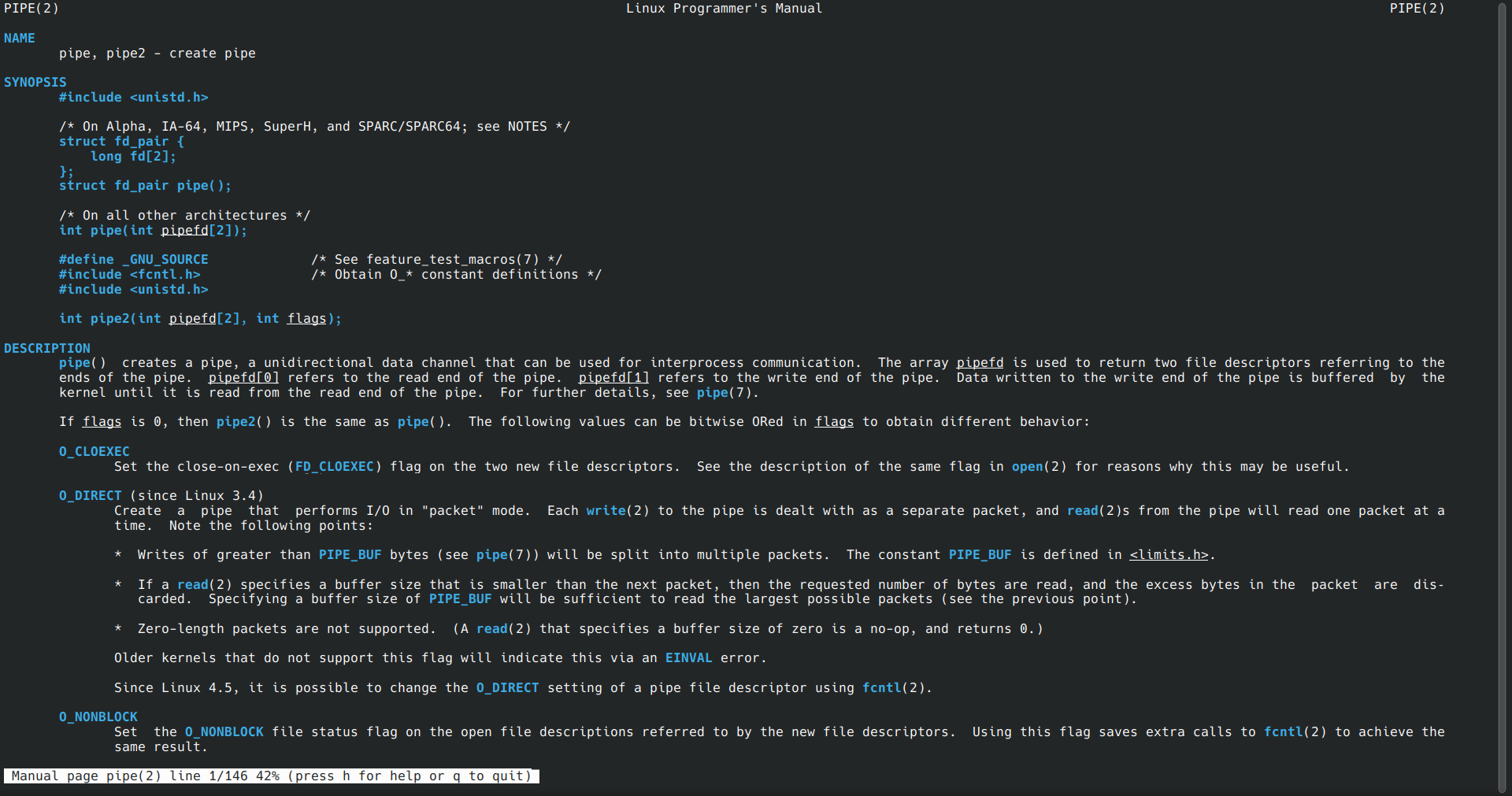
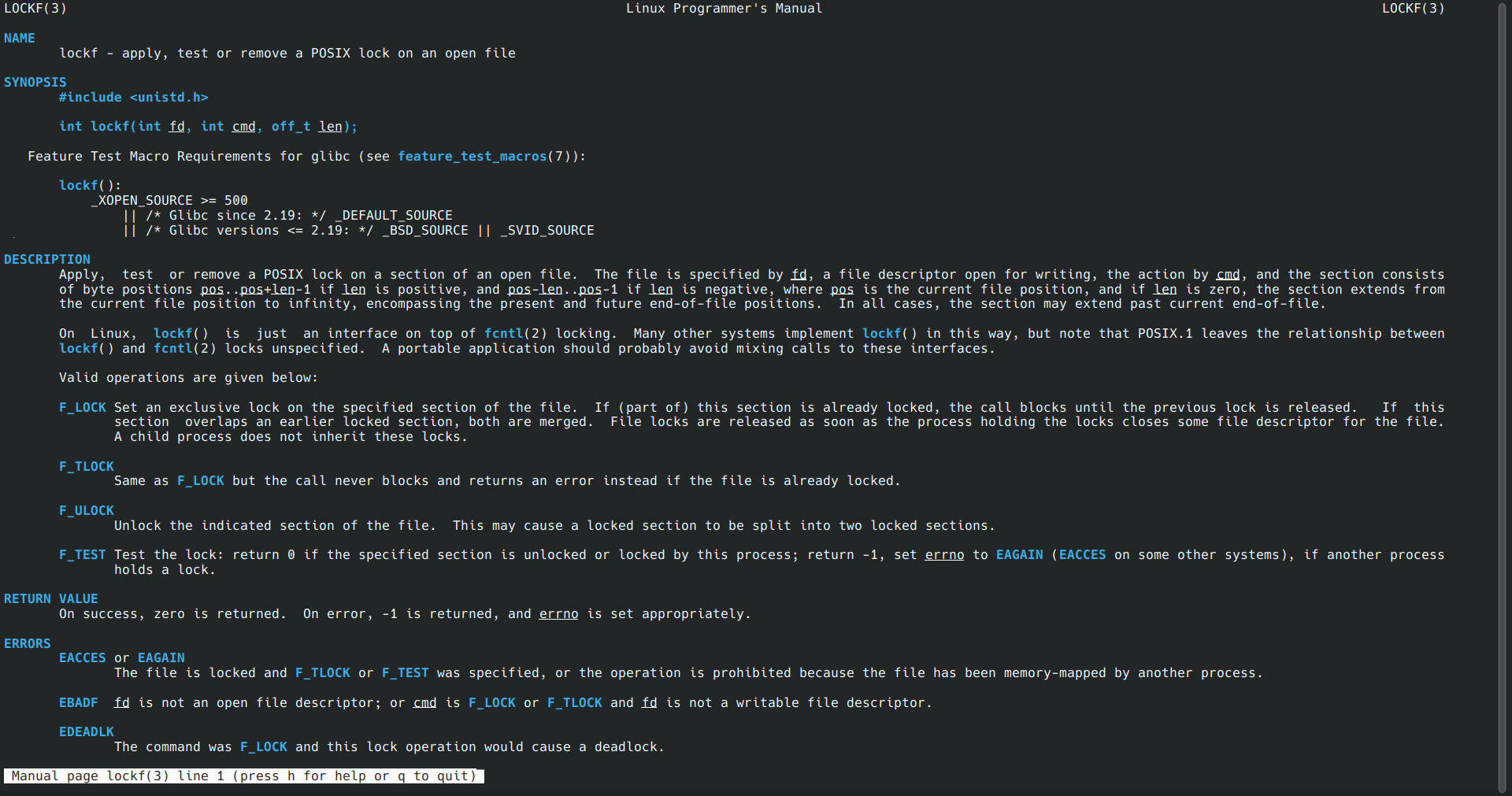
同时查阅相关博客,链接如下:
补充代码
根据注释补充代码后如下:
/*管道通信实验程序残缺版 */
#include <unistd.h>
#include <signal.h>
#include <stdio.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <string.h>
int pid1,pid2; // 定义两个进程变量
int main( )
{
int fd[2];
char InPipe[1000]; // 定义读缓冲区
pipe(fd); // 创建管道
while((pid1 = fork( )) == -1); // 如果进程 1 创建不成功,则空循环
if(pid1 == 0)
{ // 如果子进程 1 创建成功,pid1 为进程号
lockf(fd[1],1,0); // 锁定管道
char OutPipe[1000] = "Child process 1 is sending message!";
write(fd[1], OutPipe, sizeof(OutPipe)-1);
sleep(1); // 等待读进程读出数据
lockf(fd[1],0,0); // 解除管道的锁定
exit(0); // 结束进程 1
}
else
{
while((pid2 = fork()) == -1); // 若进程 2 创建不成功,则空循环
if(pid2 == 0)
{
lockf(fd[1],1,0);
char OutPipe[1000] = "Child process 2 is sending message!";
write(fd[1], OutPipe, sizeof(OutPipe)-1);
sleep(1);
lockf(fd[1],0,0);
exit(0);
}
else
{
wait(0); // 等待子进程 1 结束
wait(0); // 等待子进程 2 结束
close(fd[1]);
read(fd[0], InPipe, sizeof(InPipe)-1); // 从管道中读出 4000 个字符
InPipe[999] = 0; // 加字符串结束符
printf("%s\n",InPipe); // 显示读出的数据
exit(0); // 父进程结束
}
}
return 0;
}
但是在已运行过程中发现:
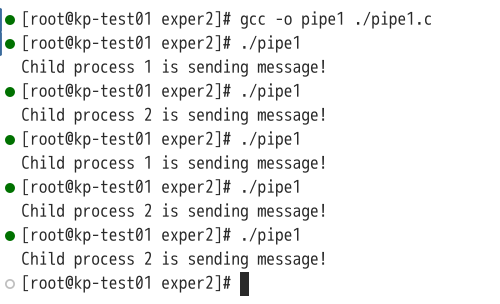
可见运行后结果中只有一个子进程向管道发送的信息被读取。分析后可知,在使用sizeof函数时,返回的并非字符串的长度,而是字符串的最大长度,修改代码使用strlen后两个子进程的信息都能被读取,如下图:
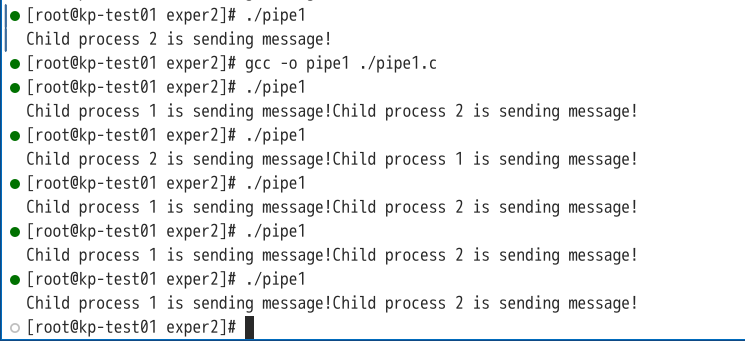
此时两个信息都被正常读取,而由于子进程执行时间不一致,导致两个子进程写操作的先后顺序有差异。 修改代码,去掉lockf函数后,运行结果如下图:
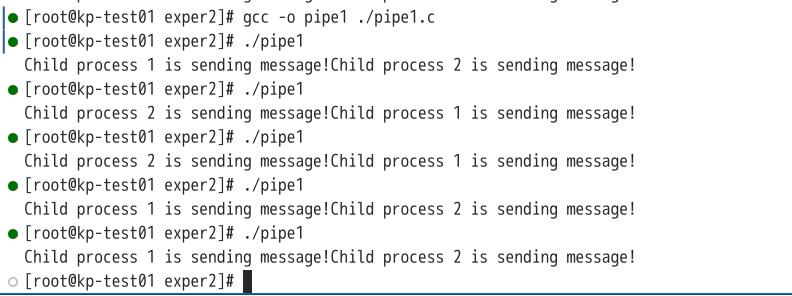
可以发现结果没有差异,查阅以下资料可知:
当要写入的数据量不大于管道容量(PIPE_BUF)时,linux会保证写入的原子性,而由于linux内部管道的缓冲区默认大小为4KB,远大于子进程发送的信息,故即使没有加锁,结果仍然会输出两个子进程发送的信息。
修改代码
根据实验要求,修改代码,使得两个子进程分别单独的发送2000个字符,父进程读取。在加锁的情况下,修改后代码如下:
/*管道通信实验程序残缺版 */
#include <unistd.h>
#include <signal.h>
#include <stdio.h>
#include <sys/wait.h>
#include <stdlib.h>
int pid1,pid2; // 定义两个进程变量
int main( )
{
int fd[2];
char InPipe[4001]; // 定义读缓冲区
char c1='1', c2='2';
pipe(fd); // 创建管道
while((pid1 = fork( )) == -1); // 如果进程 1 创建不成功,则空循环
if(pid1 == 0)
{ // 如果子进程 1 创建成功,pid1 为进程号
lockf(fd[1],1,0); // 锁定管道
char input[2000] = {'1'};
for (int i = 0; i < 2000; i++)
{
write(fd[1], input, 1); // 分 2000 次每次向管道写入字符’1’
}
sleep(5); // 等待读进程读出数据
lockf(fd[1],0,0); // 解除管道的锁定
exit(0); // 结束进程 1
}
else
{
while((pid2 = fork()) == -1); // 若进程 2 创建不成功,则空循环
if(pid2 == 0)
{
lockf(fd[1],1,0);
char input[2000] = {'2'};
for (int i = 0; i < 2000; i++)
{
write(fd[1], input, 1); // 分 2000 次每次向管道写入字符’2’
}
sleep(5);
lockf(fd[1],0,0);
exit(0);
}
else
{
wait(0); // 等待子进程 1 结束
wait(0); // 等待子进程 2 结束
close(fd[1]);
read(fd[0], InPipe, 4000); // 从管道中读出 4000 个字符
InPipe[4000] = 0; // 加字符串结束符
printf("%s\n",InPipe); // 显示读出的数据
exit(0); // 父进程结束
}
}
return 0;
}
编译后运行结果如下:

可见两个子进程发送的信息分别独立的输出,没有产生混合。修改代码为不加锁,运行结果如下:
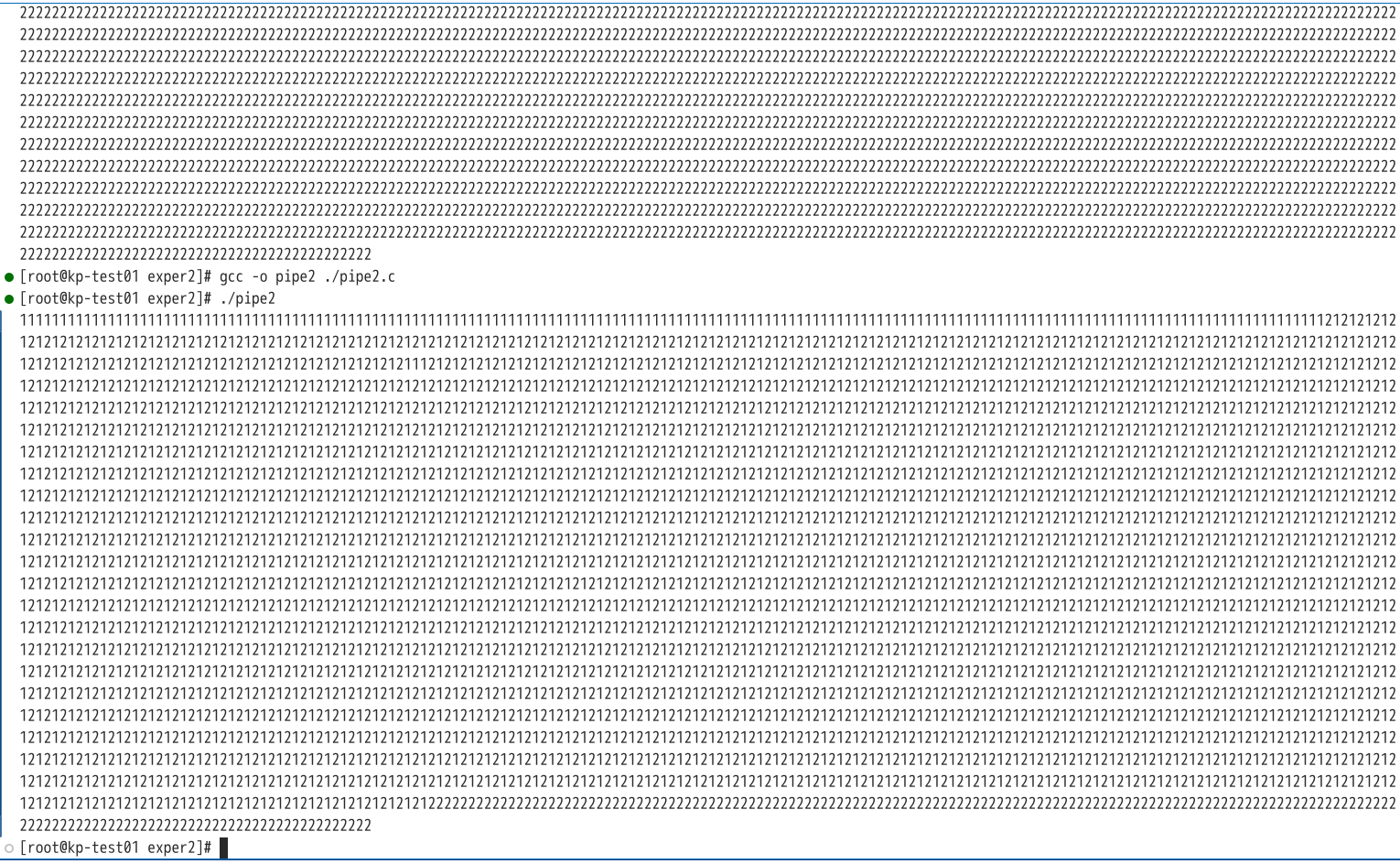
可见此时代码输出为两个子进程消息的混合。虽然Linux系统中管道的每一个操作此时仍然是原子的,但由于每次写入‘1’‘2’时是分开写入的,无法在保证每个子进程整体写入的原子性。
页面的置换
FIFO
根据算法的流程图编写代码有:
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
typedef struct _page
{
bool InsideOrUsed; // 是否在内存中或者是否被使用
int PageNumber; // ap中对应的页号或者pp中对应的页号
}Page;
int main()
{
int pp = 10; // 进程总共的页面数
int ap = 5; // 内存为此进程分配的页面数
int length = 19; // 程序运行使用的页面序列长度
int flag = 0; // 是否手动输入
printf("请输入pp、ap值:");
scanf("%d,%d", &pp, &ap);
printf("请输入运行序列长度:");
scanf("%d", &length);
printf("是否手动输入序列(1:手动,0:随机):");
scanf("%d", &flag);
Page page[pp];
Page pageContrl[ap];
for(int i=0;i<pp;i++)
{
page[i].InsideOrUsed = false;
page[i].PageNumber = -1;
}
for(int i=0;i<ap;i++)
{
pageContrl[i].InsideOrUsed = false;
pageContrl[i].PageNumber = -1;
}
int cur_ap = 0; //指向下一个内存待分配页面的指针
int run[length]; // 使用的页面序列
if(flag)
{
for(int i=0;i<length;i++)
{
scanf("%d", &run[i]);
printf("%d ", run[i]);
}
}
else
{
for(int i=0;i<length;i++)
{
run[i] = rand() % pp;
printf("%d ", run[i]);
}
}
int diseffect = 0;
for (int i = 0; i < length; i++)
{
int cur = run[i];
if (page[cur].InsideOrUsed == true)
{
printf("\npage %d in frame %d already", cur, page[cur].PageNumber);
continue;
}
page[cur].InsideOrUsed = true;
page[cur].PageNumber = cur_ap;
diseffect++;
if (pageContrl[cur_ap].InsideOrUsed == false)
{
pageContrl[cur_ap].InsideOrUsed = true;
pageContrl[cur_ap].PageNumber = cur;
printf("\npage %d in frame %d", cur, cur_ap);
cur_ap = (cur_ap + 1) % ap;
}
else
{
printf("\npage %d in frame %d replace page %d", cur, cur_ap, pageContrl[cur_ap].PageNumber);
page[pageContrl[cur_ap].PageNumber].InsideOrUsed = false;
pageContrl[cur_ap].InsideOrUsed = true;
pageContrl[cur_ap].PageNumber = cur;
cur_ap = (cur_ap + 1) % ap;
}
}
double rate = diseffect / (double)length;
rate = rate * 100;
printf("\nrate = diseffect / total_instruction*100%% = %.2f%%\n", rate);
return 0;
}
考虑到在FIFO算法中,需要加入的页面无论是内存中有的,还是有空位新加入的,都可以添加到ap列表指针的当前位置,替换算法实现较为简便,此时运行结果如图:
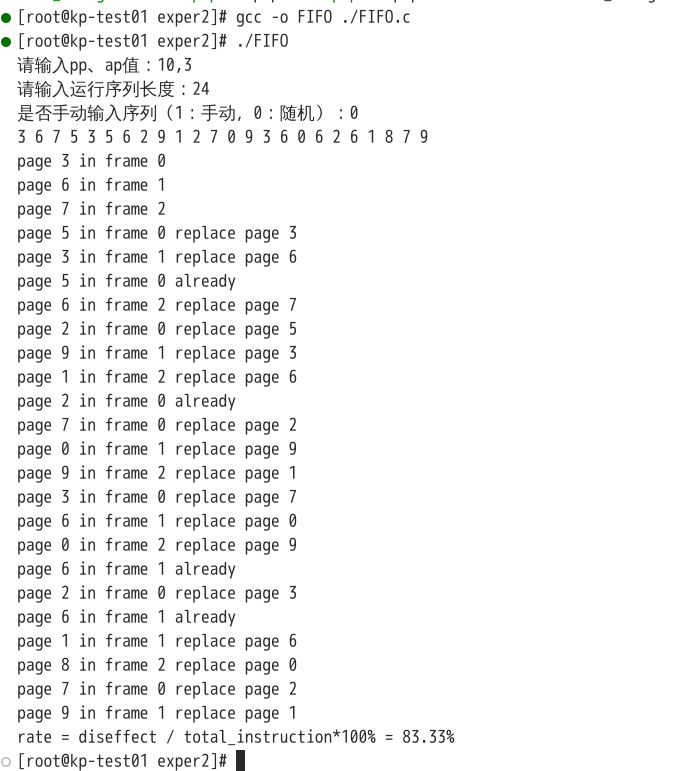
可见结果与预期相符,符合FIFO算法的计算结果。
LRU
对于LRU页面置换算法,在内存分配的页面数已经全部被使用,而下一个需要使用的页面还不在内存中时,需要将已经在内存中但距离上一次使用时间最短的页面替换出来。修改代码,使得对于内存分配的页面增添一个属性,即wait,衡量该页面未被使用的时间,在每一次替换页面或者加入页面时,使得未被使用的页面wait值加一。替换时则替换wait值最大的页面。
修改后代码如下:
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
typedef struct _page
{
bool InsideOrUsed; // 是否在内存中或者是否被使用
int PageNumber; // ap中对应的页号或者pp中对应的页号
}Page;
typedef struct _pagec
{
bool InsideOrUsed; // 是否在内存中或者是否被使用
int PageNumber; // ap中对应的页号或者pp中对应的页号
int wait; // 页面等待未使用的次数
}PageC;
int main()
{
int LRU = 1; // 使用的页面置换算法
int pp = 10; // 进程总共的页面数
int ap = 5; // 内存为此进程分配的页面数
int length = 19; // 程序运行使用的页面序列长度
int flag = 0; // 是否手动输入
printf("选择使用的页面置换算法(1:LRU, 0:FIFO):");
scanf("%d", &LRU);
printf("请输入pp、ap值:");
scanf("%d,%d", &pp, &ap);
printf("请输入运行序列长度:");
scanf("%d", &length);
printf("是否手动输入序列(1:手动,0:随机):");
scanf("%d", &flag);
Page page[pp];
PageC pageContrl[ap];
for(int i=0;i<pp;i++)
{
page[i].InsideOrUsed = false;
page[i].PageNumber = -1;
}
for(int i=0;i<ap;i++)
{
pageContrl[i].InsideOrUsed = false;
pageContrl[i].PageNumber = -1;
pageContrl[i].wait = 0;
}
int run[length]; // 使用的页面序列
if(flag)
{
for(int i=0;i<length;i++)
{
scanf("%d", &run[i]);
printf("%d ", run[i]);
}
}
else
{
for(int i=0;i<length;i++)
{
run[i] = rand() % pp;
printf("%d ", run[i]);
}
}
int diseffect = 0;
if (LRU)
{
for (int i = 0; i < length; i++)
{
int cur = run[i];
for(int j=0;j<ap;j++)
{
pageContrl[j].wait++;
}
if(page[cur].InsideOrUsed == true)
{
pageContrl[page[cur].PageNumber].wait = 0;
printf("\npage %d in frame %d already", cur, page[cur].PageNumber);
continue;
}
diseffect++;
int maxWait = 0;
bool hasEmpty = false;
for(int j=0;j<ap;j++)
{
if(pageContrl[j].InsideOrUsed == false)
{
maxWait = j;
hasEmpty = true;
break;
}
if(pageContrl[j].wait > pageContrl[maxWait].wait)
{
maxWait = j;
}
}
if(hasEmpty)
{
printf("\npage %d in frame %d", cur, maxWait);
}
else
{
printf("\npage %d in frame %d replace page %d", cur, maxWait, pageContrl[maxWait].PageNumber);
}
pageContrl[maxWait].InsideOrUsed = true;
pageContrl[maxWait].PageNumber = cur;
pageContrl[maxWait].wait = 0;
page[cur].InsideOrUsed = true;
page[cur].PageNumber = maxWait;
}
}
else
{
int cur_ap = 0; //指向下一个内存待分配页面的指针
for (int i = 0; i < length; i++)
{
int cur = run[i];
if (page[cur].InsideOrUsed == true)
{
printf("\npage %d in frame %d already", cur, page[cur].PageNumber);
continue;
}
page[cur].InsideOrUsed = true;
page[cur].PageNumber = cur_ap;
diseffect++;
if (pageContrl[cur_ap].InsideOrUsed == false)
{
pageContrl[cur_ap].InsideOrUsed = true;
pageContrl[cur_ap].PageNumber = cur;
printf("\npage %d in frame %d", cur, cur_ap);
cur_ap = (cur_ap + 1) % ap;
}
else
{
printf("\npage %d in frame %d replace page %d", cur, cur_ap, pageContrl[cur_ap].PageNumber);
page[pageContrl[cur_ap].PageNumber].InsideOrUsed = false;
pageContrl[cur_ap].InsideOrUsed = true;
pageContrl[cur_ap].PageNumber = cur;
cur_ap = (cur_ap + 1) % ap;
}
}
}
double rate = diseffect / (double)length;
rate = rate * 100;
printf("\nrate = diseffect / total_instruction*100%% = %.2f%%\n", rate);
return 0;
}
编译后运行结果如下:
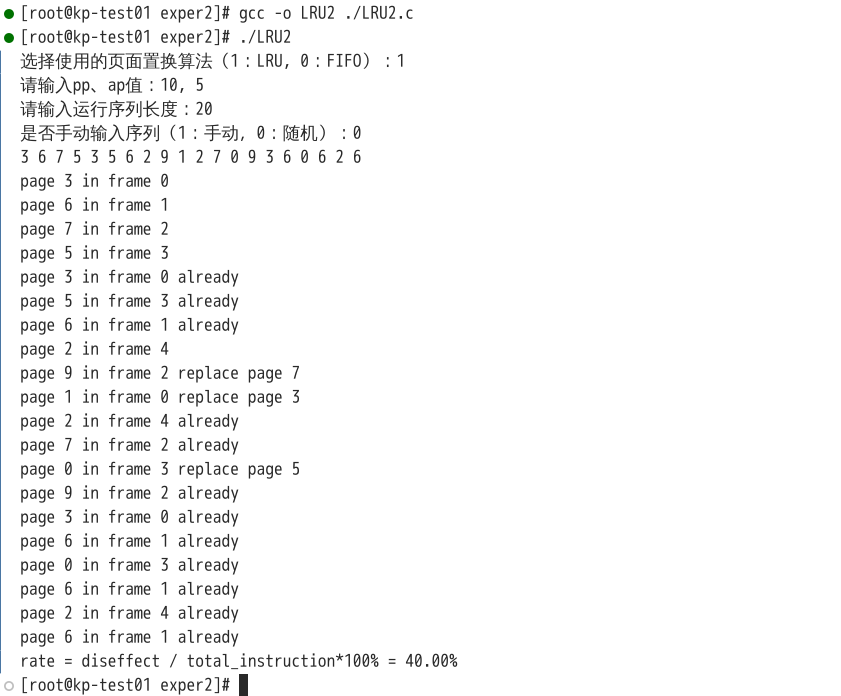
可见运行结果符合题意,每次替换时,替换了最长时间没有使用的页面
该序列使用FIFO算法的结果如下: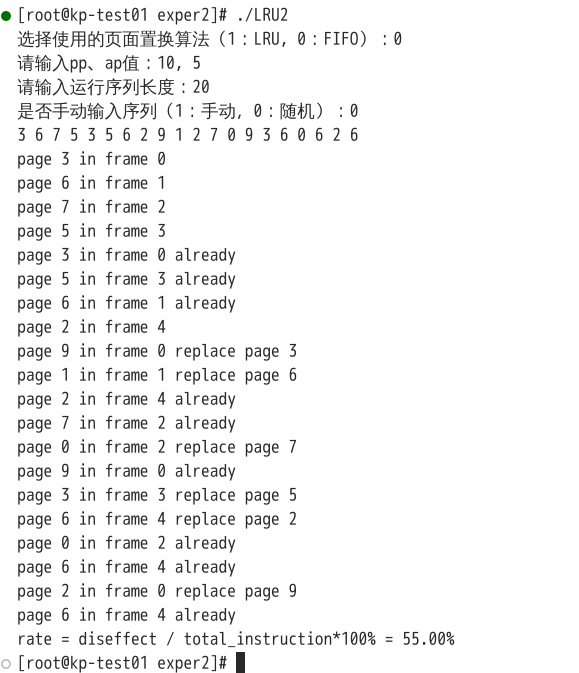
可见使用LRU的结果缺页率更小。
测试数据设计
Bleady
BLEADY现象(Belady’s Anomaly)是指在某些页面置换算法(例如FIFO,即先进先出算法)中,给进程分配更多的物理页面并不会减少页面错误(Page Faults),反而可能增加页面错误次数的现象。 FIFO 算法在页面频繁切换时,会导致早期页面的置换。据此设计以下测试数据: pp = 10, ap = 3/4, length = 12, run = {1 2 3 4 1 2 5 1 2 3 4 5}
编译后运行结果如下:
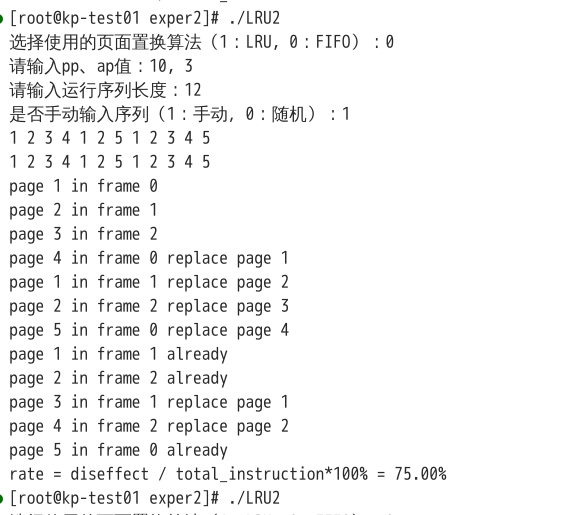
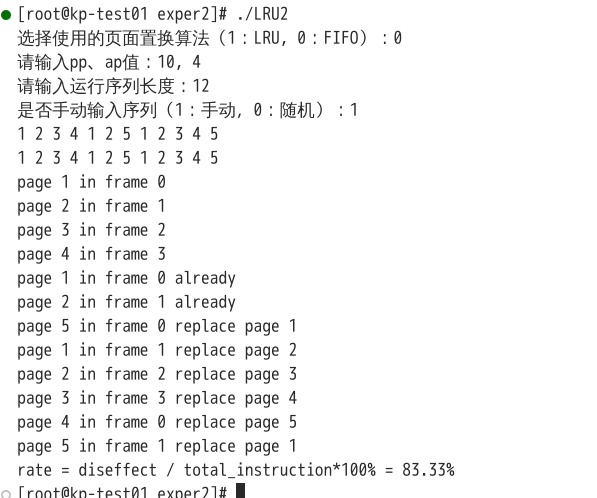
可见在页面框数增大的情况下,缺页率反而增加。
局部性数据
在LRU算法中,更体现了程序运行的局部性原理,为体现FIFO和LRU算法的差异,设计测试数据如下:
pp = 10, ap = 4, length = 20, run = {0 1 2 3 0 1 2 3 4 5 6 7 4 5 6 7 0 1 2 3}
两种不同的算法编译后运行结果如下:


结果如图,可见LRU算法在针对有局部性特点的数据时,表现更优。